Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Un operador SQL (versión preliminar), también denominado editor de código SQL, es una nueva funcionalidad de transformación de datos en las secuencias de eventos de Microsoft Fabric. Los operadores SQL proporcionan una experiencia de edición de código donde puede definir fácilmente su propia lógica de transformación de datos personalizada mediante expresiones SQL simples. En este artículo se describe cómo usar un operador SQL para transformaciones de datos en una secuencia de eventos.
Note
Los nombres de artefactos de eventstream que incluyen un carácter de subrayado (_) o punto (.) no son compatibles con los operadores SQL. Para obtener la mejor experiencia, cree una nueva secuencia de eventos sin usar caracteres de subrayado ni puntos en el nombre del artefacto.
Prerequisites
- Acceso a un área de trabajo en el modo de licencia de capacidad de Fabric o el modo de licencia de prueba con permisos Colaborador o superior.
Adición de un operador SQL a una secuencia de eventos
Para realizar operaciones de procesamiento de flujos en los flujos de datos mediante un operador SQL, agregue un operador SQL a la secuencia de eventos mediante las instrucciones siguientes:
Cree una nueva secuencia de eventos. A continuación, agregue un operador SQL a él mediante una de las siguientes opciones:
En la cinta de opciones, seleccione Transformar eventos y, a continuación, seleccione SQL.
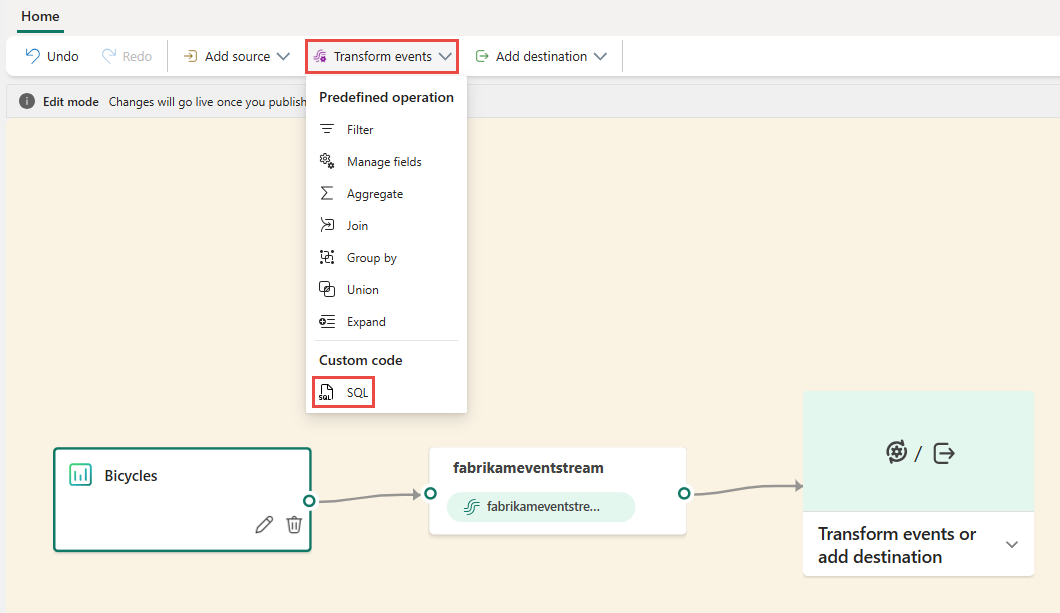
En el lienzo, seleccione Transformar eventos o agregar destino y, a continuación, seleccione Código SQL.

Se agrega un nuevo nodo SQL al flujo de eventos. Seleccione el icono de lápiz para continuar configurando el operador SQL.
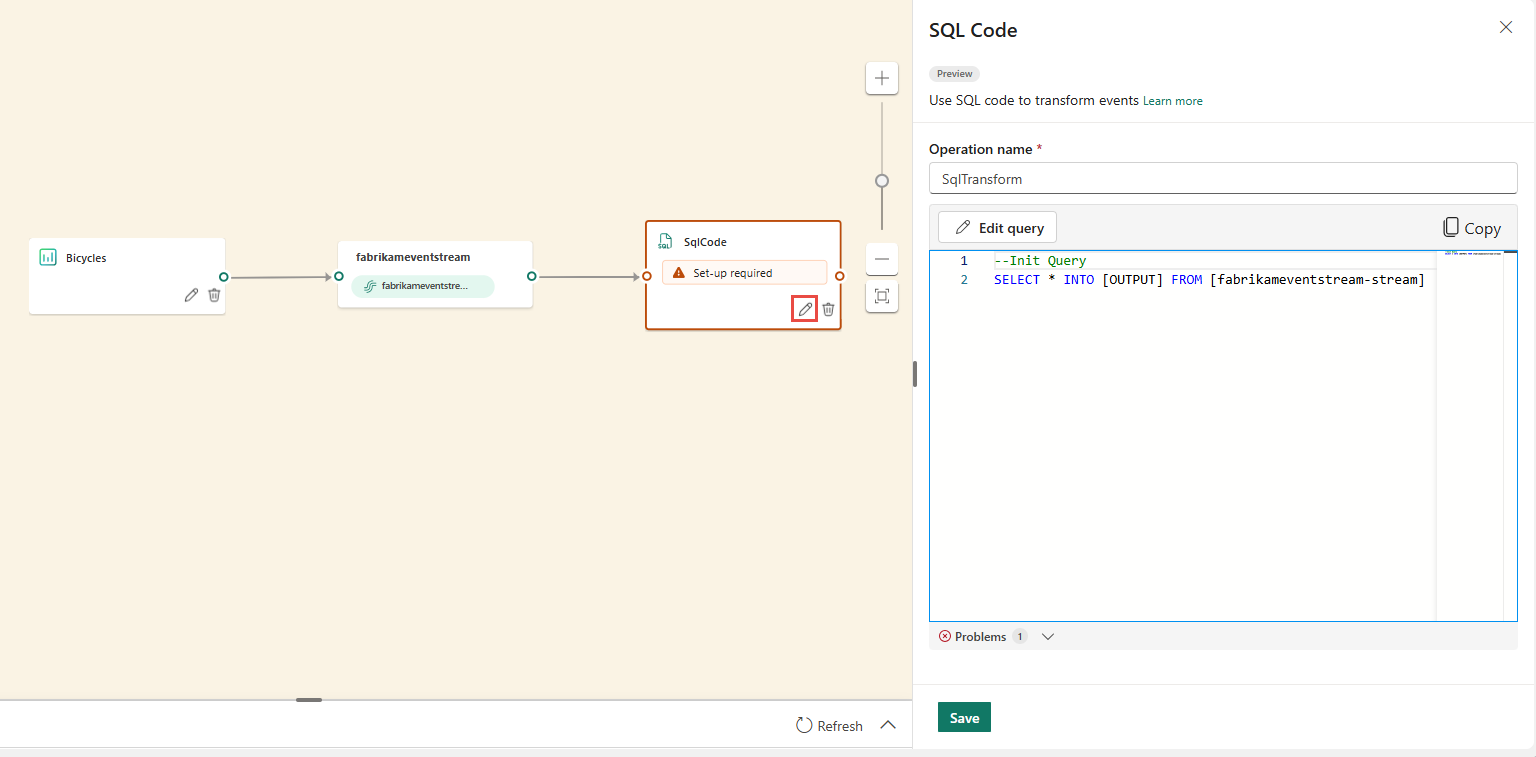
En el panel Código SQL , especifique un nombre único para el nodo del operador SQL en el flujo de eventos.
Edite la consulta en el área de consulta o seleccione Editar consulta para ingresar a la vista del editor de código en pantalla completa.

El modo de editor de código de pantalla completa incluye un panel del explorador de entrada/salida en el lado izquierdo. La sección del editor de código es ajustable, por lo que puede cambiar su tamaño según sus preferencias. La sección de vista previa de la parte inferior le permite ver los datos de entrada y el resultado de la prueba de la consulta.

Seleccione el texto de la sección Salidas y escriba un nombre para el nodo de destino. El operador SQL admite todos los destinos de inteligencia de Real-Time, incluido un centro de eventos, lakehouse, activador o secuencia.

Especifique un alias o un nombre para el destino de salida donde se escriben los datos procesados a través del operador SQL.

Agregue una consulta SQL para la transformación de datos necesaria.
Una secuencia de eventos se basa en Azure Stream Analytics y admite la misma semántica de consulta del lenguaje de consulta de Stream Analytics. Para obtener más información sobre la sintaxis y el uso, consulte Azure Stream Analytics y Eventstream Query Language Reference.
Esta es la estructura de consulta básica:
SELECT column1, column2, ... INTO [output alias] FROM [input alias]En este ejemplo de consulta se muestra la detección de temperaturas altas en una sala cada minuto:
SELECT System.Timestamp AS WindowEnd, roomId, AVG(temperature) AS AvgTemp INTO output FROM input GROUP BY roomId, TumblingWindow(minute, 1) HAVING AVG(temperature) > 75En este ejemplo de consulta se muestra una
CASEinstrucción para clasificar la temperatura:SELECT deviceId, temperature, CASE WHEN temperature > 85 THEN 'High' WHEN temperature BETWEEN 60 AND 85 THEN 'Normal' ELSE 'Low' END AS TempCategory INTO CategorizedTempOutput FROM SensorInputEn la cinta de opciones, use el comando Test query para validar la lógica de transformación. Los resultados de la consulta de prueba aparecen en la pestaña Resultado de la prueba .

Cuando finalice la prueba, seleccione Guardar en la cinta de opciones para volver al lienzo de eventstream.

En el panel Código SQL , si el botón Guardar está habilitado, selecciónelo para guardar la configuración.

Configura el destino.











Más ejemplos
En los ejemplos siguientes se muestran escenarios comunes de análisis en tiempo real que puede implementar con el operador SQL.
Agregación de ventas por ciudad por minuto : se usa TumblingWindow para calcular totales fijos y no superpuestos de ventas de un minuto agrupados por ciudad:
SELECT
System.Timestamp AS WindowEnd,
city,
SUM(salesAmount) AS TotalSales
INTO
output
FROM
input
GROUP BY
city,
TumblingWindow(minute, 1)
Detección de ráfagas y bots : use HoppingWindow para detectar usuarios que coloquen un número inusualmente alto de pedidos en un período gradual de cinco minutos, evaluados cada minuto:
SELECT
System.Timestamp AS WindowEnd,
userId,
COUNT(*) AS OrderCount
INTO
output
FROM
input
GROUP BY
userId,
HoppingWindow(minute, 5, 1)
HAVING
COUNT(*) > 10
Anomalías marcadas con una línea base gradual : se usa HoppingWindow para calcular un promedio gradual y marcar los dispositivos cuyo valor máximo de métrica supera el doble del promedio dentro de la ventana, lo que indica una posible anomalía:
SELECT
System.Timestamp AS WindowEnd,
deviceId,
AVG(metricValue) AS RollingAvg,
MAX(metricValue) AS CurrentMax
INTO
output
FROM
input
GROUP BY
deviceId,
HoppingWindow(minute, 10, 1)
HAVING
MAX(metricValue) > 2 * AVG(metricValue)
Escritura en varios destinos desde un único operador SQL
Con el operador SQL, puede enviar datos a varios receptores de salida o destinos agregando varias INTO cláusulas en la consulta SQL y definiendo varias salidas.
Definición de varias salidas en el editor de consultas
Seleccione Editar (icono de lápiz) en el nodo operador SQL para abrir el panel Código SQL .
En el panel Código SQL , seleccione Editar consulta para abrir el editor de código de pantalla completa.
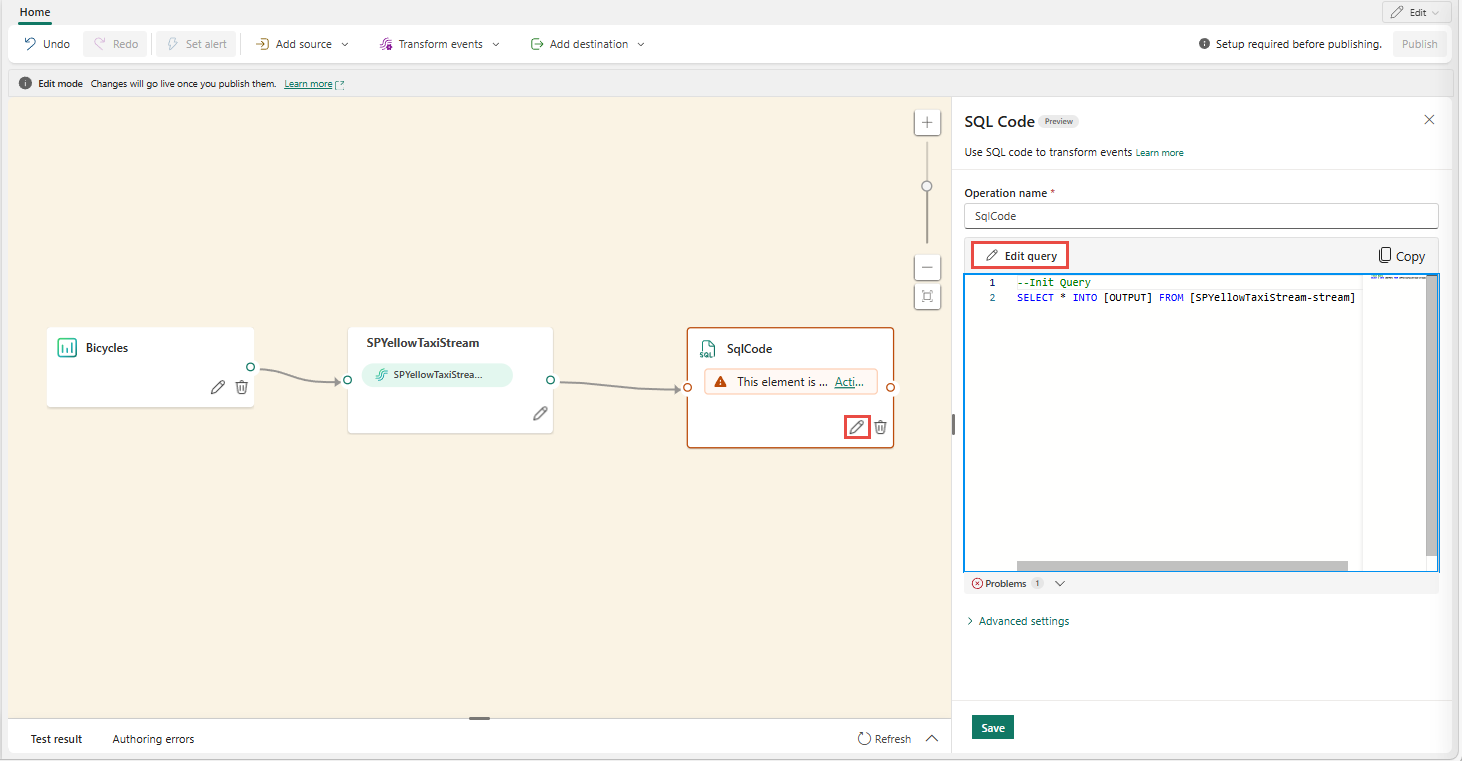
En el editor de código de pantalla completa, seleccione + en la sección Salidas para agregar una nueva salida. Seleccione el tipo de salida que prefiera. Crea un alias de la salida que se puede usar en una consulta. Seleccione el nombre de la salida creada y escriba un nombre de su elección.



Usa múltiples instrucciones SELECT ... INTO
Cada SELECT instrucción puede escribir en una salida diferente. Agregue la consulta para escribir la salida en varios destinos.
En el ejemplo de consulta siguiente, la primera SELECT instrucción escribe en una salida denominada RawArchive (tipo: Lakehouse) y la segunda SELECT instrucción escribe en una salida denominada AggregationResults (tipo: Eventhouse).
-- Query 1: Archive all data to Lakehouse
SELECT *
INTO [RawArchive]
FROM [SQLDemoES-stream]
-- Query 2: Aggregate and filter data to create a real time dashboard to an Eventhouse
SELECT System.Timestamp() AS EventTime, COUNT(*) AS EventCount
INTO [AggregationResults]
FROM [SQLDemoES-stream]
GROUP BY TumblingWindow(minute, 1)
HAVING COUNT(*) > 100
Reutilización de la lógica intermedia (procedimiento recomendado)
Si desea evitar la duplicación de la lógica, use una cláusula WITH y distribuya las salidas a múltiples destinos desde allí. En el ejemplo siguiente, la InputStream expresión de tabla común (CTE) se define para leer desde el flujo de entrada una vez y, a continuación, las dos SELECT instrucciones hacen referencia al InputStream CTE para escribir en diferentes salidas. Este enfoque es más eficaz porque evita la lectura del flujo de entrada varias veces.
Escriba la consulta siguiente en el editor de código SQL para leer del flujo de entrada una vez y escribir en varias salidas.
--Base query: Reading input stream once With InputStream AS( SELECT * FROM [SQLDemoES-stream] ) -- Query 1: Archive all data to Lakehouse SELECT * INTO [RawArchive] FROM InputStream -- Query 2: Aggregate and filter data to create a real time dashboard to an Eventhouse SELECT System.Timestamp() AS EventTime, COUNT(*) AS EventCount INTO [AggregationResults] FROM InputStream GROUP BY TumblingWindow(minute, 1) HAVING COUNT(*) > 100Seleccione Test query (Probar consulta ) para validar el resultado de la consulta. Cada salida definida en la consulta tiene una pestaña independiente en el panel Resultados de la prueba .

Seleccione Guardar para guardar la consulta y salir del editor.

Seleccione Guardar de nuevo en el panel Editor de SQL.
Seleccione cada nodo de destino creado desde el operador SQL y, a continuación, configure las opciones de destino para cada uno de ellos.

Después de finalizar la configuración, el flujo de eventos debe ser similar al ejemplo siguiente, donde el nodo del operador SQL tiene dos destinos de salida.
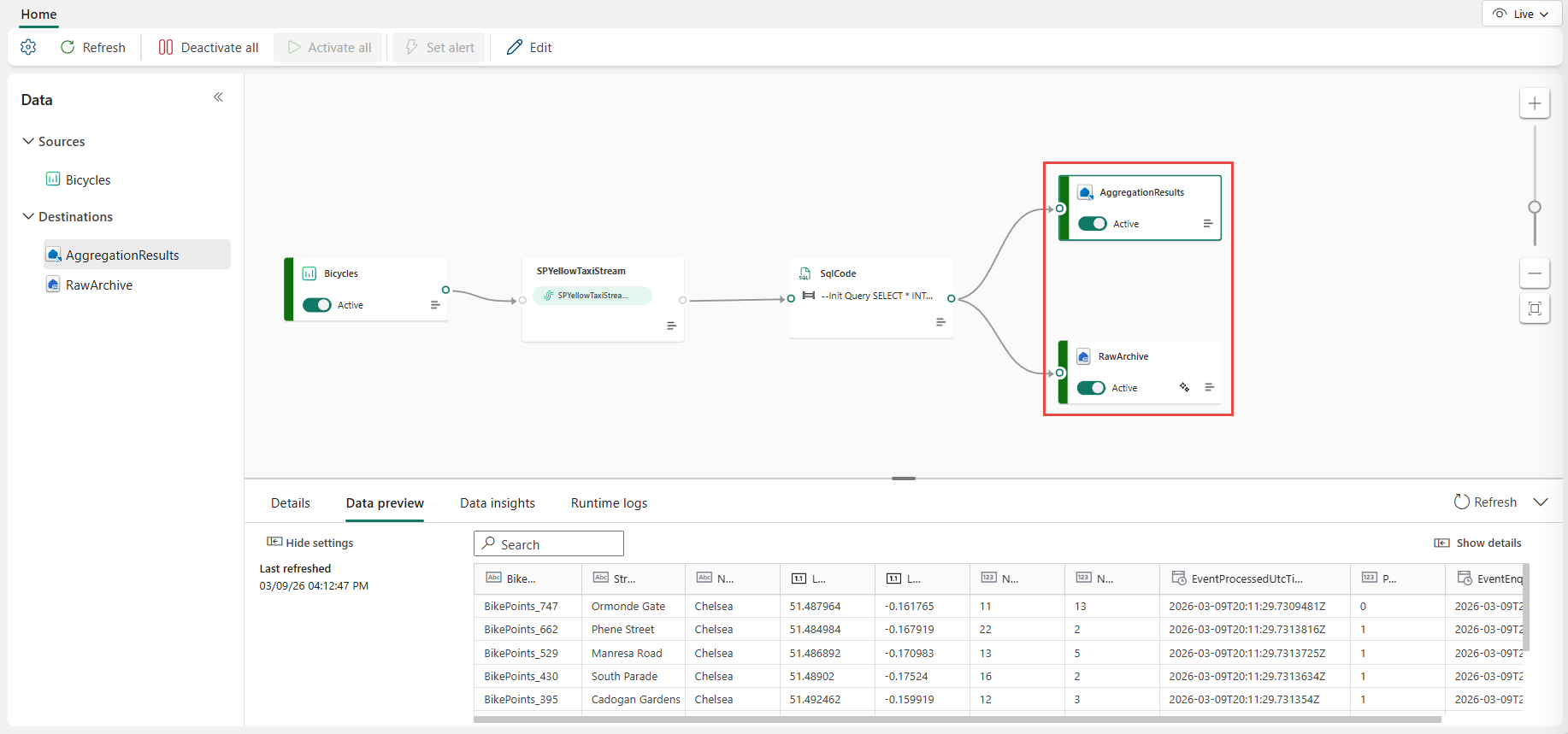




Configuración de directivas de ordenación de eventos en el operador SQL
Con el operador SQL, puede procesar datos mediante el evento o la hora de la aplicación. De forma predeterminada, Eventstream usa la hora de llegada. Para procesar por tiempo de evento, debe configurarlo explícitamente mediante TIMESTAMP BY en la consulta.
Entrada de ejemplo
{
"deviceId": "device123",
"temperature": 72,
"eventTime": "2024-01-01T12:00:00Z"
}
Consulta de ejemplo mediante la hora del evento
SELECT
deviceId,
temperature,
System.Timestamp() AS EventTimestamp
INTO
Output
FROM
Input
TIMESTAMP BY eventTime;
También puede agregar umbrales para los eventos de llegada tardía y desorden en la configuración avanzada del operador SQL.

Limitations
El operador SQL está diseñado para centralizar toda la lógica de transformación. Como resultado, no se puede usar junto con otros operadores integrados dentro de la misma ruta de procesamiento. Tampoco se admite el encadenamiento de varios operadores SQL en una sola ruta de acceso.
El operador SQL puede enviar datos de salida solo al nodo de destino de la topología.
Actualmente, la creación de topologías de eventstream solo se admite a través de la interfaz de usuario. La compatibilidad con la API REST para el operador SQL aún no está disponible.