Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Un operatore SQL (anteprima), detto anche editor di script SQL, è una nuova funzionalità di trasformazione dei dati nei flussi di eventi di Microsoft Fabric. Gli operatori SQL offrono un'esperienza di modifica del codice in cui è possibile definire facilmente la propria logica di trasformazione dei dati personalizzata usando semplici espressioni SQL. Questo articolo descrive come usare un operatore SQL per le trasformazioni dei dati in un flusso di eventi.
Note
I nomi degli artefatti eventstream che includono un carattere di sottolineatura (_) o punto (.) non sono compatibili con gli operatori SQL. Per un'esperienza ottimale, creare un nuovo flusso di eventi senza usare caratteri di sottolineatura o punti nel nome dell'artefatto.
Prerequisites
- Accesso a un'area di lavoro nella modalità licenza della capacità Fabric o nella modalità di licenza di valutazione con autorizzazioni da Collaboratore o superiore.
Aggiungere un operatore SQL a un flusso di eventi
Per eseguire operazioni di elaborazione del flusso sui flussi di dati usando un operatore SQL, aggiungere un operatore SQL al flusso di eventi usando le istruzioni seguenti:
Creare un nuovo flusso di eventi. Aggiungere quindi un operatore SQL usando una delle opzioni seguenti:
Sulla barra multifunzione selezionare Trasforma eventi, e quindi selezionare SQL.

Nell'area di disegno selezionare Trasforma eventi o aggiungi destinazione e quindi selezionare Codice SQL.
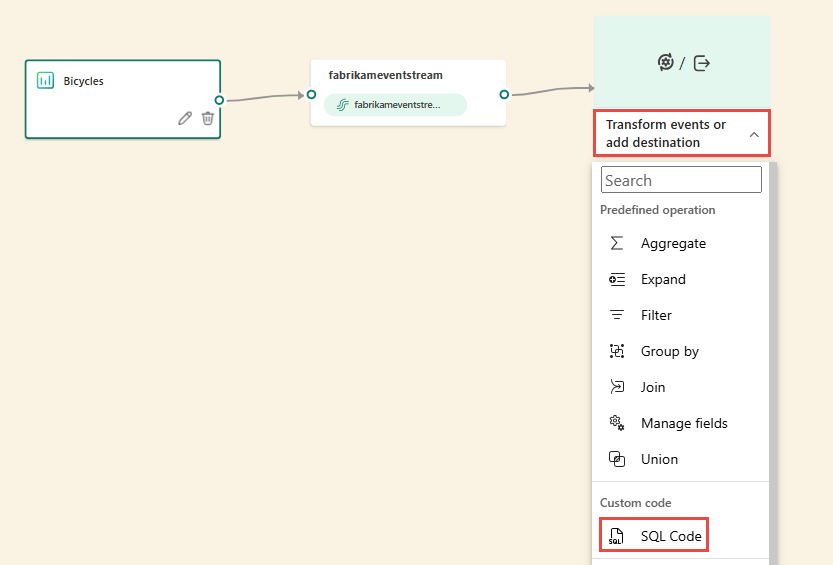
Un nuovo nodo SQL viene aggiunto al flusso di eventi. Selezionare l'icona a forma di matita per continuare a configurare l'operatore SQL.

Nel riquadro Codice SQL specificare un nome univoco per il nodo dell'operatore SQL nel flusso di eventi.
Modificare la query nell'area query oppure selezionare Modifica query per immettere la visualizzazione dell'editor di codice a schermo intero.

La modalità editor di codice a schermo intero include un esploratore input/output sul lato sinistro. La sezione dell'editor di codice è modificabile, in modo da poterla ridimensionare in base alle preferenze. La sezione di anteprima nella parte inferiore consente di visualizzare sia i dati di input che il risultato del test della query.

Selezionare il testo nella sezione Output e quindi immettere un nome per il nodo di destinazione. L'operatore SQL supporta tutte le destinazioni di intelligence Real-Time, tra cui una eventhouse, una lakehouse, un attivatore o un flusso.

Specificare un alias o un nome per la destinazione di output in cui vengono scritti i dati elaborati tramite l'operatore SQL.

Aggiungere una query SQL per la trasformazione dei dati richiesta.
Un flusso di eventi si basa su Azure Stream Analytics e supporta la stessa semantica delle query del linguaggio di query di Analisi di flusso. Per ulteriori informazioni sulla sintassi e sull'utilizzo, consultare il Riferimento del linguaggio di query di Eventstream di Azure Stream Analytics.
Ecco la struttura base della query:
SELECT column1, column2, ... INTO [output alias] FROM [input alias]Questo esempio di query mostra il rilevamento di temperature elevate in una stanza ogni minuto:
SELECT System.Timestamp AS WindowEnd, roomId, AVG(temperature) AS AvgTemp INTO output FROM input GROUP BY roomId, TumblingWindow(minute, 1) HAVING AVG(temperature) > 75Questo esempio di query mostra un'istruzione
CASEper classificare la temperatura:SELECT deviceId, temperature, CASE WHEN temperature > 85 THEN 'High' WHEN temperature BETWEEN 60 AND 85 THEN 'Normal' ELSE 'Low' END AS TempCategory INTO CategorizedTempOutput FROM SensorInputSulla barra multifunzione usare il comando Query di test per convalidare la logica di trasformazione. I risultati della query di test vengono visualizzati nella scheda Risultati test .

Al termine del test, selezionare Salva sulla barra multifunzione per tornare all'area di disegno eventstream.

Nel riquadro Codice SQL , se il pulsante Salva è abilitato, selezionarlo per salvare le impostazioni.

Configurare la destinazione.











Altri esempi
Gli esempi seguenti illustrano scenari comuni di analisi in tempo reale che è possibile implementare con l'operatore SQL.
Aggregazione delle vendite di città al minuto : usare TumblingWindow per calcolare i totali delle vendite fissi e non sovrapposti di un minuto raggruppati per città:
SELECT
System.Timestamp AS WindowEnd,
city,
SUM(salesAmount) AS TotalSales
INTO
output
FROM
input
GROUP BY
city,
TumblingWindow(minute, 1)
Rilevamento di burst e bot : consente HoppingWindow di rilevare gli utenti che effettuano un numero insolitamente elevato di ordini entro un intervallo di cinque minuti, valutato ogni minuto:
SELECT
System.Timestamp AS WindowEnd,
userId,
COUNT(*) AS OrderCount
INTO
output
FROM
input
GROUP BY
userId,
HoppingWindow(minute, 5, 1)
HAVING
COUNT(*) > 10
Contrassegno anomalie rispetto a una linea di base mobile : usare HoppingWindow per calcolare una media mobile e contrassegnare i dispositivi il cui valore massimo della metrica supera il doppio della media all'interno della finestra, che indica un'anomalia potenziale:
SELECT
System.Timestamp AS WindowEnd,
deviceId,
AVG(metricValue) AS RollingAvg,
MAX(metricValue) AS CurrentMax
INTO
output
FROM
input
GROUP BY
deviceId,
HoppingWindow(minute, 10, 1)
HAVING
MAX(metricValue) > 2 * AVG(metricValue)
Scrivere in più destinazioni da un singolo operatore SQL
Con l'operatore SQL è possibile inviare dati a più sink o destinazioni di output aggiungendo più INTO clausole nella query SQL e definendo più output.
Definire più output nell'editor di query
Selezionare Modifica (icona a forma di matita) nel nodo dell'operatore SQL per aprire il riquadro Codice SQL .
Nel riquadro Codice SQL selezionare Modifica query per aprire l'editor di codice a schermo intero.
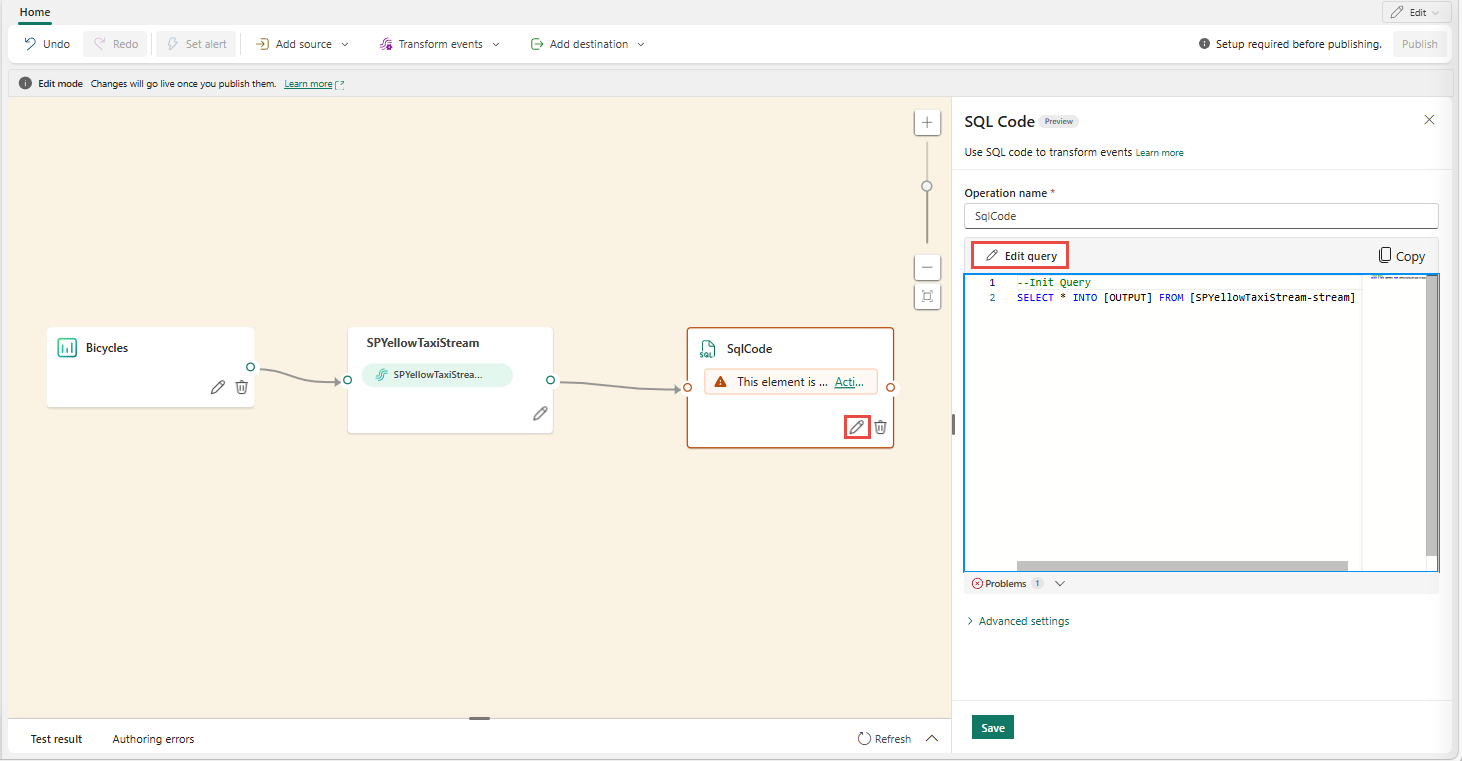
Nell'editor di codice a schermo intero selezionare + nella sezione Output per aggiungere un nuovo output. Selezionare il tipo di output desiderato. Crea un alias dell'output che è possibile usare in una query. Selezionare il nome dell'output creato e immettere un nome di propria scelta.



Usare più istruzioni SELECT ... INTO
Ogni SELECT istruzione può scrivere in un output diverso. Aggiungi la query per indirizzare l'output su più destinazioni.
Nell'esempio di query seguente la prima SELECT istruzione scrive in un output denominato RawArchive (tipo: Lakehouse) e la seconda SELECT istruzione scrive in un output denominato AggregationResults (tipo: Eventhouse).
-- Query 1: Archive all data to Lakehouse
SELECT *
INTO [RawArchive]
FROM [SQLDemoES-stream]
-- Query 2: Aggregate and filter data to create a real time dashboard to an Eventhouse
SELECT System.Timestamp() AS EventTime, COUNT(*) AS EventCount
INTO [AggregationResults]
FROM [SQLDemoES-stream]
GROUP BY TumblingWindow(minute, 1)
HAVING COUNT(*) > 100
Riutilizzare la logica intermedia (procedura consigliata)
Se si vuole evitare la duplicazione della logica, usare una clausola WITH ed eseguire l'espansione in più output da lì. Nell'esempio seguente, l'espressione InputStream di tabella comune (CTE) viene definita per leggere dal flusso di input una sola volta e quindi le due SELECT istruzioni fanno riferimento al InputStream CTE per scrivere su uscite diverse. Questo approccio è più efficiente perché evita la lettura dal flusso di input più volte.
Immettere la seguente query nell'editor di codice SQL per leggere dal flusso di input in una sola operazione e scrivere verso più flussi di output.
--Base query: Reading input stream once With InputStream AS( SELECT * FROM [SQLDemoES-stream] ) -- Query 1: Archive all data to Lakehouse SELECT * INTO [RawArchive] FROM InputStream -- Query 2: Aggregate and filter data to create a real time dashboard to an Eventhouse SELECT System.Timestamp() AS EventTime, COUNT(*) AS EventCount INTO [AggregationResults] FROM InputStream GROUP BY TumblingWindow(minute, 1) HAVING COUNT(*) > 100Selezionare Test query per convalidare il risultato della query. Ogni output definito nella query ha una scheda separata nel pannello Risultati test .

Selezionare Salva per salvare la query e uscire dall'editor.

Selezionare di nuovo Salva nel riquadro Editor SQL.
Selezionare ogni nodo di destinazione creato dall'operatore SQL e quindi configurare le impostazioni di destinazione per ognuna di esse.

Al termine della configurazione, il flusso di eventi dovrebbe essere simile all'esempio seguente, in cui il nodo dell'operatore SQL ha due destinazioni di output.





Configurare i criteri di ordinamento degli eventi nell'operatore SQL
Con l'operatore SQL è possibile elaborare i dati usando l'ora dell'evento o dell'applicazione. Per impostazione predefinita, Eventstream usa l'ora di arrivo. Per elaborare in base all'ora dell'evento, è necessario configurarlo in modo esplicito usando TIMESTAMP BY nella query.
Input di esempio
{
"deviceId": "device123",
"temperature": 72,
"eventTime": "2024-01-01T12:00:00Z"
}
Query di esempio usando l'ora dell'evento
SELECT
deviceId,
temperature,
System.Timestamp() AS EventTimestamp
INTO
Output
FROM
Input
TIMESTAMP BY eventTime;
È anche possibile aggiungere soglie per gli eventi di arrivo in ritardo e non in ordine nelle impostazioni avanzate dell'operatore SQL.

Limitations
L'operatore SQL è progettato per centralizzare tutta la logica di trasformazione. Di conseguenza, non è possibile usarlo insieme ad altri operatori predefiniti all'interno dello stesso percorso di elaborazione. Anche il concatenamento di più operatori SQL in un singolo percorso non è supportato.
L'operatore SQL può inviare dati di output solo al nodo di destinazione nella topologia.
Attualmente, la creazione di topologie eventstream è supportata solo tramite l'interfaccia utente. Il supporto dell'API REST per l'operatore SQL non è ancora disponibile.